Durch digitale Medien kann jeder einfach auf eine Vielzahl von Informationskanälen zugreifen, um sich zu informieren bzw. sich informiert zu fühlen und um Informationen, aber auch Meinungen und Desinformation zu verbreiten. Informierten sich früher viele durch die Tageszeitung ihrer Wahl, so bieten die digitalen Medien heute eine Vielzahl scheinbar kostenloser Angebote. Das Problem mit diesen ist jedoch, dass sie durch Werbeeinnahmen finanziert werden und teilweise entsprechend versuchen, Leser mit weniger sachlichen und sehr emotionalen Artikeln zu binden sowie Klicks und damit Einnahmen zu generieren. Längerfristige Ziele der Qualitätssicherung stehen dahinter zurück. Diese Entwicklung wird durch die vermehrte Nutzung von „Social Media“-Kanälen verstärkt.
Das digitale Informationsumfeld ist anfällig gegenüber Beeinflussung und kann dazu genutzt werden, gesellschaftliche Prozesse zu manipulieren. Wie resilient eine Gesellschaft gegenüber Beeinflussung ist, hängt auch damit zusammen, wie (gut) sie informiert ist. Wie leicht falsche oder fehlende Informationen zu einer Bedrohung werden können, kann man aktuell an der Corona-Krise beobachten. Gelangen einseitige oder falsche Informationen in Umlauf, kann dies wirtschaftliche Schäden anrichten und sogar Leben kosten.
Es ist daher wichtig, Entwicklungen im öffentlichen Informationsraum zu beobachten und Ereignisse zu erkennen, um daraus für das eigene Handeln zeitnah die richtigen Schlüsse zu ziehen. Das Fraunhofer-Institut für Kommunikation, Informationsverarbeitung und Ergonomie FKIE führt Kompetenzen unterschiedlicher Disziplinen zusammen, um mit „News Hawk“ Werkzeuge zur Verfügung zu stellen, die eine entsprechende Lagefeststellung erlauben.

Erfassen von Daten aus dem öffentlichen Informationsraum
Die erste Hürde für die Beobachtung und Analyse im öffentlichen Informationsraum ist das Erfassen der Daten. Prinzipiell können alle Informationen, die über Webseiten zugänglich sind, durch sogenannte Crawler automatisiert eingesammelt werden. Die Herausforderung ist dabei die Extraktion des Informationsinhalts einer Webseite. Einem Menschen fällt dies leicht, ein Algorithmus muss es aber erst „lernen”. Die zweite Herausforderung liegt in der Menge der verfügbaren Information. Es ist allenfalls für Google möglich, das gesamte Internet zu durchsuchen und in Datenbanken zu indizieren. Entsprechend müssen Einstiegspunkte für den Teil des Internets festgelegt werden, der beachtet werden soll. Über die Verlinkung der Webseiten gelangt man dann zu weiterführender oder verwandter Information auf anderen Seiten.
Hier muss der Algorithmus eine intelligente Auswahl treffen, um sich nicht in der Weiterverfolgung zu verlieren. Weitere Webseiten und Inhalte lassen sich auch über Beiträge in sozialen Medien erfassen, da diese oft Verweise zu externen Quellen enthalten. Dabei gelangt man auch zu unkonventionellen Webseiten, die gezielt verwendet werden, um Falschinformationen mit dem Anstrich einer seriösen Berichterstattung zu verbreiten. Die in den sozialen Medien unmittelbar verbreiteten Informationen sind ebenfalls von Interesse. Sie haben zudem den Vorteil, dass für sie eine Verknüpfung der Inhalte zu den Nutzern, die sie veröffentlichen, teilen oder bewerten, hergestellt werden kann. Das liefert Kontextinformation und ermöglicht eine Analyse dazu, wie sich Informationen über „Social Media“-Kanäle verbreiten.
Viele „Social Media“-Plattformen bieten Entwicklern eine API, um Inhalte gezielt abzurufen. Die Twitter-API erlaubt es, Inhalte stichwortbezogen zu suchen. Twitter erleichtert zudem die Inhaltserschließung von Tweets, indem Nutzer ihre Beiträge unter Verwendung des #-Zeichens mit Schlagwörtern versehen können. Diese Twitter-Idee wurde von anderen übernommen und ist mittlerweile Standard. Twitter versteht sich als Kurznachrichtendienst und stuft das, was gepostet wird, als öffentlich ein. Anders sehen das Facebook und Instagram, die sich als Freundesnetzwerk verstehen. Daher gibt es hier geschützte Bereiche, in denen Informationen nur für einen beschränkten Nutzerkreis sichtbar sind. Nutzer können Beiträge aber auch öffentlich teilen. Diese können dann über eine API abgefragt werden. Allerdings erlaubt Facebook dabei keine stichwort-, sondern lediglich die nutzerbezogene Abfrage von Inhalten.
Über Instagram werden Bildinhalte geteilt, die mit Text und Hashtags versehen sein können. Instagrams API erlaubt in einer kostenpflichtigen Version zumindest die Abfrage zu Hashtags, allerdings nur in einem stark begrenzten Umfang. Die YouTube-API wiederum ermöglicht es, mit Stichwörtern in Titeln und Beschreibungstexten von Videos zu suchen. Interessant sind in vielen Fällen die Kommentare zu Beiträgen. Diese können allerdings nur bezogen auf den Beitrag und nicht über eine Suche abgerufen werden. Da auf Plattformen wie Instagram und YouTube Inhalt per Bild bzw. Video transportiert wird, müssen Bildauswertungsverfahren für die inhaltliche Analyse genutzt werden. Das gilt mittlerweile auch für andere Kanäle. Über Twitter beispielsweise werden mittlerweile ebenfalls Beiträge in Form von Fotos oder Videos veröffentlicht.
Generell sind bei der Verwendung erfasster Daten Nutzungsbedingungen zu berücksichtigen. Diese beziehen sich allerdings in der Regel auf die kommerzielle Weiterverwertung. Trotzdem sind Prüfungen notwendig, insbesondere wenn personenbezogene Daten erfasst werden.
Analyse von Daten aus dem öffentlichen Informationsraum
Um Textdaten analysieren zu können, müssen diese einer Verarbeitung unterzogen werden. Dafür eignen sich die Verfahren des Natural Language Processing (NLP). Die Fragestellungen, die bei einer solchen Vorverarbeitung behandelt werden, reichen von der Identifikation von Schlüsselwörtern bis zur semantisch-inhaltlichen Aufbereitung. Dabei dient die Identifikation von Schlüsselwörtern der Kategorisierung der Texte, während die inhaltliche Aufbereitung genutzt wird, um Fragen an den Text zu beantworten.
Eine wesentliche Vorverarbeitung ist die sogenannte „Named Entity Recognition“ (NER), deren Ergebnisse nicht nur als Vorstufe der inhaltlichen Analyse benötigt werden, sondern auch für sich genommen wertvoll sind. Bei der NER werden Wörter und Wortsequenzen annotiert, welche auf Personen, Organisationen, Orte etc. verweisen. Informationen darüber, welche Entitäten zusammen vorkommen, sind für Analysten bereits von Interesse. In Verbindung mit einer tieferen inhaltlichen Analyse können aber auch Aussagen über die Relationen, die zwischen den Entitäten gelten, gemacht werden. Das System kann dann in natürlicher Sprache formulierte Abfragen beantworten, indem die formulierte Anfrage ebenfalls in ihre semantischen Anteile zerlegt wird und dadurch mit den erfassten Daten abgeglichen werden kann.
Neben Textinhalten sollte der Inhalt von Bildern und Videos erfasst werden. Bei Videos ist die Tonspur relevant, sofern das in ihr Gesagte automatisiert verschriftlicht werden kann. Für das Erkennen von Bildinhalten gibt es bereits KI-Verfahren. Sie sind Gegenstand aktueller Forschung. Robuster sind Algorithmen, die Texte in Bildern erkennen und extrahieren (OCR – Optical Character Recognition). Diese Technik ist relevant, weil in sozialen Medien Kernbotschaften häufig durch sogenannte Memes verbreitet werden: Bilder von einem Text mit prägnanter Aussage.
Erfasste Inhalte können vorher definierten Klassen zugewiesen und damit kategorisiert werden. Die Klassen müssen dabei nicht inhaltsbezogen sein. So sind auch „enthält Orthographiefehler“ oder „enthält Hate Speech“ mögliche Klassen-Label. Sowohl für Texte als auch für Bilder müssen Klassifikatoren über Beispiele „trainiert” werden. Dazu eignen sich KI-Verfahren wie „Deep Learning“. Obwohl diese viel Rechenkapazität benötigen, kommt das Resultat, das trainierte Modell, bei der Klassifikation selbst mit geringen Ressourcen aus. Alternativ werden Daten über „selbstlernende“ Verfahren strukturiert. Diese benutzen statistische Maße wie Worthäufigkeiten, um Texte mit ähnlichem Inhalt zu gruppieren. Die Zuordnung muss nicht eindeutig sein, da ein Text oder ein Bild zu verschiedenen Themen passen kann. Dies wird etwa im Ansatz des Topic Modeling berücksichtigt.
Das Auffinden von Themen ist ein wichtiger Ansatz, um Narrative zu erkennen und deren Verbreitung und Änderung zu verstehen. Narrative sind sinnstiftende Erzählungen. Über sie werden Werte und Emotionen transportiert. Sie haben Einfluss darauf, wie die Umwelt wahrgenommen wird, und können damit gut zur Beeinflussung missbraucht werden.
Um die Verbreitung von Information und Beeinflussung in den sozialen Medien zu verstehen, ist die Analyse der Beziehungen zwischen den Nutzern nützlich. Dies ist in sozialen Netzwerken möglich, da sich die Nutzer hier über Inhalte austauschen, sei es durch eine Bewertung, Kommentierung oder das Weiterleiten. Entsprechend können Beziehungen zwischen Nutzern abgeleitet werden: Wer folgt wem? Wer leitet welche Nachrichten von wem weiter? Welche Nachrichten wurden von wem kommentiert? Wer wurde in welchen Nachrichten von wem erwähnt? Eine Visualisierung bzw. Analyse dieser Zusammenhänge zeigt, wie einflussreich Nutzer in Bezug auf bestimmte Themen sind.
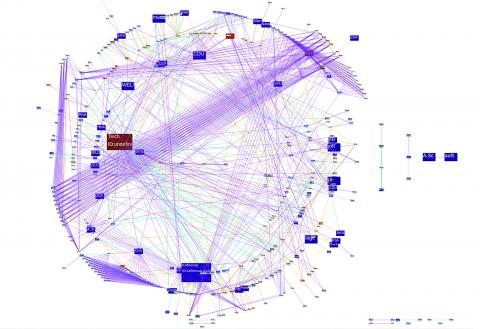
IViD – Plattform für die visuelle Analyse von Inhalten in Graph-Datenbanken
Visual Analytics ist ein interdisziplinärer Ansatz, um komplexe und große Datensätze so aufzubereiten, dass Nutzer diese intuitiv analysieren können. Dazu werden Datenbanktechnologien und automatisierte Analyseverfahren mit einer interaktiven graphischen Benutzungsschnittstelle verknüpft. Interaktive Visualisierungen erlauben die intuitive Exploration durch direkte Interaktion. Eine besondere Rolle spielen in unserem Kontext Graph-Datenbanken, in welchen etwa Relationen zwischen „Named Entities“, aber auch die Netzwerke der Nutzer abgelegt werden.
Fraunhofer FKIE hat ein generisches Visual Analytics Framework entwickelt, mit dem für Inhalte von Graph-Datenbanken schnell interaktive Dashboards für die Visualisierung und Exploration erstellt werden können. So werden Analysen optimiert. Sind beispielsweise zu Nutzern sowie zu Beiträgen Verteilungsstatistiken angezeigt, etwa eine Herkunftsverteilung der Nutzer und eine Hashtagverteilung der Beiträge, so zieht die Filterung in der einen Verteilung, etwa die Einschränkung der Nutzer auf solche in Berlin, die Anpassung der anderen Verteilung nach sich. Auf diese Weise lassen sich leicht Zusammenhänge zwischen verschiedenen Statistiken explorieren.
News Hawk
Basierend auf dem generischen Framework zur interaktiven Visualisierung hat Fraunhofer FKIE die Analyse-Plattform „News Hawk“ entwickelt, mit der Informationen aus dem öffentlichen Informationsraum analysiert werden können. News Hawk verfügt über die angesprochenen Fähigkeiten, von der Datensammlung und deren Verarbeitung, über Kategorisierungs- und Clusterverfahren bis hin zur Visualisierung im Sinne von Visual Analytics.
News Hawk sollte auf die gewünschte Aufgabe angepasst werden, was die Einbindung des Nutzers erfordert. Das FKIE-Team steht daher in einem engen Informationsaustausch mit unterschiedlichen Stellen der Bundeswehr sowie diversen Behörden und Partnern.
Crisis Prevention 3/2020
Dr. Carsten Winkelholz
Forschungsgruppenleiter „Informationsvisualisierung und Interaktion“
Fraunhofer-Institut für Kommunikation, Informationsverarbeitung und Ergonomie FKIE
Fraunhoferstr. 20, 53343 Wachtberg
Tel.: +49 228 9435-494
E-Mail: carsten.winkelholz@fkie.fraunhofer.de
https://www.fkie.fraunhofer.de
Prof. Dr. Ulrich Schade
Forschungsgruppenleiter „Informationsanalyse
Tel.: +49 228 9435-376
E-Mail: ulrich.schade@fkie.fraunhofer.de