Wie kann Künstliche Intelligenz bei der Annahme von Notrufen unterstützen
ein Forschungsansatz
Matthias Haack, Anastasiia Kysliak, Ivana Kruijff-Korbayová, Udo Brandhuber, Monika Schnattler
Die sogenannte Künstliche Intelligenz (KI) ist als Zukunftstechnologie aktuell in aller Munde. Bei der vermeintlichen KI handelt es sich zumeist um lernfähige Algorithmen, die eine spezifische Aufgabe – bspw. im Bereich der Datenanalyse – erfüllen sollen und die darauf ausgelegt sind, sich anhand der bislang erzielten Ergebnisse selbsttätig zu optimieren (sog. „schwache“ KI). Obgleich dabei eine Art Lernprozess und bestimmte Formen der menschlichen Entscheidungsfindung abgebildet werden, handelt es sich lediglich um Werkzeuge, die den Menschen bei der Lösung mathematisch-modellierbarer Aufgabenstellungen unterstützen. Ein aus dem Alltag bekannter Anwendungsbereich ist das Erkennen sowie die semantische Analyse der menschlichen Sprache. Aktuell kommt diese Technologie vor allem in Mobiltelefonen sowie der Haus- und Unterhaltungselektronik zur Anwendung. In den letzten Jahren hat die Leistungsfähigkeit dieser Systeme stetig zugenommen, wodurch die Erschließung neuer Anwendungsbereiche ermöglicht wurde. Im Bereich der Gefahrenabwehr ist das Erkennen und Interpretieren des gesprochenen Wortes insbesondere bei der Übermittlung von Notfallmeldungen relevant. Es scheint daher naheliegend, zu prüfen, inwiefern automatische Sprachverarbeitung geeignet ist, bei der Telekommunikation z.B. in Feuerwehr- und Rettungsleitstellen zu unterstützen. Sollte es bspw. gelingen, mittels eines digitalen Sprachassistenten Zeitvorteile bei der Notrufannahme herauszuarbeiten, könnten u.U. spezifische Hilfeleistungen schneller erbracht und Schäden von betroffenen Personen abgewendet werden.
Aus dieser Motivation heraus wurde das öffentlich geförderte Forschungsprojekt NotAs – Multilingualer Notruf Assistent: Unterstützung der Notrufannahme durch KI-basierte Sprachverarbeitung ins Leben gerufen. Das Projekt zielt darauf ab, einen digitalen Sprachassistenten für die Verwendung in Feuerwehr- und Rettungsleitstellen zu entwickeln. Hierzu sollen fortschrittliche Verfahren zur automatischen Spracherkennung, semantischen Analyse sowie maschinellen Übersetzung kombiniert werden. Es ist nicht beabsichtigt, die Notrufannahme als solche zu automatisieren, stattdessen sollen die Mitarbeitenden in den Leitstellen entlastet werden, damit Sie sich auf die Interaktion mit den hilfeersuchenden Personen konzentrieren können. Beteiligt an dem Projekt sind die eurofunk Kappacher Deutschland GmbH, das Deutsche Forschungszentrum für Künstliche Intelligenz GmbH (DFKI) sowie die Feuerwehr Dortmund als potentielle Endanwenderin und Koordinatorin des Verbundes. Das Projekt ist auf eine Laufzeit von zwei Jahren ausgelegt und startete im Oktober 2020. Als Fallstudie wurde ein Hilfeersuchen einer Person angenommen, die der deutschen Sprache nicht mächtig ist. Besteht eine Sprachbarriere zwischen der anrufenden Person und dem Leitstellenpersonal, kann es mehrere Minuten dauern, bis eine Minimalinformation (Standort der Person und Art des Notfalls) vorliegt. Dies führt eventuell zu einem Zeitverzug bis zur Erstdisposition und ggf. zu weiteren Verzögerungen, sofern eine Nachalarmierung erfolgen muss. Aktuell werden verschiedene Ansätze verfolgt, um Sprachbarrieren bei der Notrufannahme zu überwinden, z.B. Schulungen des Personals in verschiedenen Verkehrssprachen, Kooperationen zwischen Leitstellen aus unterschiedlichen Sprachräumen oder das Hinzuziehen von sprachkundigen Personen aus einer Rufbereitschaft heraus. Es können jedoch nicht für jeden Sprachhintergrund ausreichende Kapazitäten vorgehalten werden. Im Projekt NotAs soll die Spracherkennung als Schlüsseltechnologie für einen automatischen Übersetzungsdienst dienen. Ferner wird durch eine Transkription des Anrufs die Voraussetzung für eine semantische Analyse durch eine KI geschaffen. Die KI soll – unabhängig von der Sprache der anrufenden Person – bei der Erkennung relevanter Inhalte unterstützen und die Mitarbeitenden in den Leitstellen beim manuellen Übertrag von Angaben in bspw. ein Einsatzformular entlasten.
Lösungsansatz:
Um die zuvor genannten Funktionen bereitstellen zu können, sollen folgende Technologien zu einer bidirektional wirkenden Verarbeitungskette kombiniert werden:
1. Automatische Sprachidentifikation: die Identifizierung der Einzelsprache einer anrufenden Person (z.B. Deutsch, Englisch etc.).
2. Automatische Spracherkennung (Automatic Speech Recognition – ASR): die Überführung der menschlichen Sprache als Audioinformation in ein Textformat (Transkription).
3. Maschinelle Übersetzung (Machine Translation – MT): das automatische Übersetzen eines Textes in eine vorgegebene Zielsprache, bspw. Deutsch.
4. Interpretation (Natural Language Understanding – NLU): das Erkennen von relevanten Textinhalten durch eine KI gemäß vordefinierten Kategorien.
5. Text zu Sprache (Text To Speech – TTS): die Umwandlung von Text in ein Audiosignal mittels Sprachsynthese.
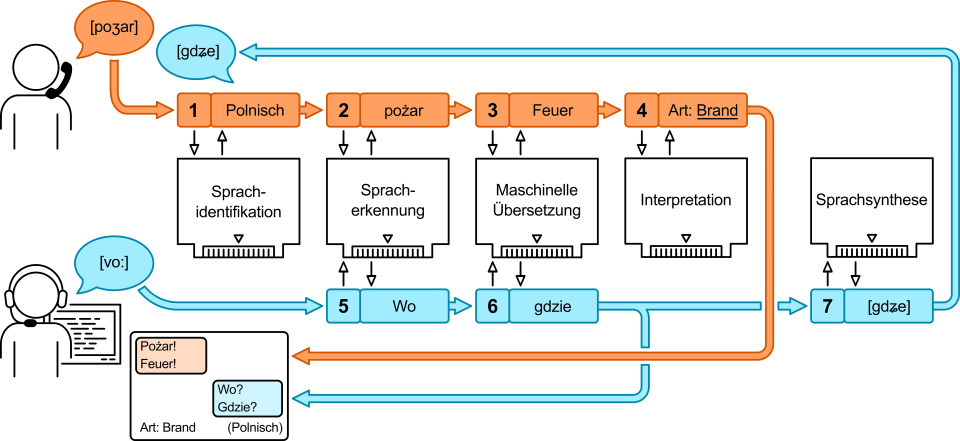
Die Verarbeitungskette ist in Abbildung 1 schematisch dargestellt. Der Ablauf während eines Anrufs gestaltet sich wie folgt: Eine hilfeersuchende Person teilt in Ihrer starken Sprache A, d.h. die Sprache, die die Person am besten beherrscht, eine Information mit. Die Einzelsprache wird identifiziert oder erfragt und das zugehörige Spracherkennungsmodul durch das System geladen (1). Mittels dieses Moduls wird die Sprache der hilfeersuchenden Person in ein Textformat umgewandelt (2). Der Text in Sprache A wird an das Übersetzungsmodul übergeben und von diesem in die starke Sprache B des Leitstellenpersonals übersetzt (3). Beide Texte werden in Form eines Transkripts am Bildschirm dargestellt, vgl. Abbildung 2. Der Text in Sprache B wird durch ein Interpretationsmodul auf relevante Inhalte hin untersucht (4). Die erkannten Inhalte werden angezeigt und zur weiteren Verarbeitung gespeichert. Umgekehrt wird eine Rückmeldung des Leitstellenpersonals in dessen starker Sprache B mittels Spracherkennung transkribiert (5) und der Text nachfolgend in die starke Sprache A der hilfeersuchenden Person übersetzt (6). Der übersetzte Text kann via Sprachsynthese in eine Audioinformation umgewandelt und über die Telefonverbindung übermittelt werden (in Planung) (7). Die einzelnen Module sind in ein Grundgerüst (Framework) eingebettet, das auch die Schnittstellen zu externen Prozessen sowie die Benutzeroberfläche bereitstellt.
Es ist zu erwarten, dass die Verständigung mittels eines solchen Assistenzsystems nicht in einer ähnlich flüssigen Form stattfinden kann, wie zwischen zwei Personen, die in einer gemeinsamen Sprache kommunizieren. Das System soll vor diesem Hintergrund als Werkzeug verstanden werden, das helfen soll, in Fällen zu vermitteln, in denen ansonsten aufgrund einer Sprachbarriere bestenfalls eine Ortsbestimmung erfolgen könnte. Ziel ist es, mit möglichst geringem Zeitaufwand eine dem Notfall angemessene Erstdisposition zu ermöglichen.
Umsetzung eines Funktionsdemonstrators:
In Rahmen der Planungsphase des Demonstrators wurde unter Beteiligung von Mitarbeitenden aus der Leitstelle der Feuerwehr Dortmund ein Anforderungskatalog erstellt, in dem die angestrebten Eigenschaften des Assistenzsystems festgeschrieben wurden. Im Zuge dessen wurden auch Marktanalysen der eurofunk Kappacher Deutschland GmbH berücksichtigt, die Meinungsbilder zahlreicher weiterer potentieller Endanwender wiedergeben.
Die Module für die Spracherkennung, Übersetzung und Interpretation nutzen lernfähige Algorithmen, die mittels sog. Trainingsdaten angelernt werden müssen. Hierzu sind Notrufgespräche erforderlich, die manuell transkribiert und annotiert wurden, also eine Zielvorgabe definieren (sog. „Goldstandard“). Im Zuge des Projektes wurde geprüft, inwiefern die Nutzung von Mitschnitten realer Notrufgespräche für Forschungszwecke möglich ist. Gemäß Feuerwehrgesetz NRW (BHKG, §46, Abs. 4) ist die Nutzung von im Rahmen der Qualitätssicherung mitgeschnittenen Notrufgesprächen zu Forschungszwecken zwar zulässig, jedoch nur in Folge einer Anonymisierung. Dies hätte jedoch dazu geführt, dass die vom System zu erkennenden Informationen (z.B. die Adresse) aus den Mitschnitten hätten entfernt werden müssen. Ein Training der KI wäre daher nicht möglich gewesen. Folglich wurde beschlossen, in dieser Entwicklungsphase simulierte Notrufgespräche als Trainingsdaten zu verwenden. Die Gespräche wurden von Angehörigen der Feuerwehr Dortmund eingesprochen. Ein Teil wurde vom assoziierten Partner Branddirektion München zur Verfügung gestellt. Im Laufe des Projektes wurde so ein relativ umfangreicher Datenpool aufgebaut. Gemessen an dem Bedarf an Trainingsdaten für ein robustes Training von KI ist die Menge der erstellten Daten allerdings zu gering. Daher wurden durch das DFKI auch gemeinfreie Trainingsdaten, z.B. aus den Projekten OPUS und MobIE verwendet, die keine Notrufgespräche sind, jedoch ähnliche Inhalte aufweisen.
Das Spracherkennungsmodul basiert auf einer kommerziell verfügbaren Software des Herstellers Nuance. Die Neuentwicklung eines eigenen Spracherkennungsmoduls läge außerhalb der Kapazitäten des Projekts und war daher keine Zielvorgabe. Auch die Nutzung einer kommerziellen Spracherkennungssoftware setzt umfangreiche Arbeiten zur Anpassung an das jeweilige Anwendungsgebiet voraus, z.B. müssen Fachbegriffe der Software bekannt sein. Für die Nutzung der Spracherkennung während einer Notrufannahme müssen darüber hinaus Informationen über den (räumlichen) Zuständigkeitsbereich der jeweiligen Leitstelle hinterlegt sein, bspw. die Namen der zu erkennenden Straßen und Ortsteile.
Das Übersetzungsmodul wurde durch das DFKI neuentwickelt. Dafür wurden vier Übersetzungsmodelle für die im Projekt verwendeten vier Übersetzungsrichtungen (Polnisch-Deutsch & Englisch-Deutsch) erstellt. Diese Modelle basieren auf der Transformer-Architektur, die sich im Bereich der Maschinellen Übersetzung bewährt hat. Die Modelle wurden u.a. daraufhin trainiert, dass bestimmte Wörter, wie z.B. Eigennamen von Straßen, Organisation und Personen, nicht wörtlich übersetzt, sondern unverändert in das Transkript übernommen werden.
Bei dem Interpretationsmodul handelt es sich ebenfalls um eine Entwicklung des DFKI auf Grundlage moderner Deep-Learning-Ansätze. Als Eingabe wird eine transkribierte Aussage in Textform erwartet, Bsp.:
„Ich wohne in der Musterstraße 7. Meine Nummer ist 0123-456789.“
Aus dem Text werden Informationen extrahiert, die semantisch vordefinierten Kategorien entsprechen. Im Projekt NotAs orientieren sich diese Kategorien an dem Konzept der fünf „W-Fragen“, bspw. ADRESSE (Wo?), NAME und TELEFONNUMMER (Wer?) etc. Die erkannten Informationen werden den passenden Kategorien zugewiesen (z.B. ADRESSE: „Musterstraße 7“; TELEFONNUMMER: „0123-456789“), zur weiteren Verarbeitung zwischengespeichert und sollen in der Benutzeroberfläche zusammengefasst dargestellt werden.
Das Framework wurde von unserem Projektpartner entwickelt und basiert auf modernen State-of-the-Art-Technologien mit dem Ziel einer hohen Verfügbarkeit und Leistungsfähigkeit des Gesamtsystems. Der Demonstrator ist modular konzipiert und die einzelnen Module laufen in sog. Containern in einem Kuber-
netes-Cluster. Dieser ist in der Lage, verstorbene Dienste vollautomatisch zu rebooten und bei Bedarf zusätzliche Instanzen desselben Dienstes zu starten. Der Demonstrator ist als Stand-Alone-Komponente ausgelegt und verfügt über Funktionen, die sich aus gesetzlichen bzw. normierten Anforderungen an den Betrieb einer Leitstelle ergeben, wie z.B. ein zentrales Logging, das über ein graphisches Werkzeug auswertbar ist. Das Frontend ist voll-webbasiert und läuft in einem Browser ohne Zusatzinstallationen am Endgerät, was die Anforderung an eine einfache und unkomplizierte Softwareverteilung Rechnung trägt.
Bisherige Ergebnisse
Der Funktionsdemonstrator ist seit April 2022 zu Testzwecken verfügbar. Er beinhaltet (Stand Juli 2022) die folgenden Funktionen: die Spracherkennung für Deutsch und Englisch in einer für den Anwendungsfall Notrufannahme erweiterten Variante, diese wurde bspw. auf das Erkennen von Ortsbezeichnungen trainiert. Ferner wurden Übersetzungsmodule für die Sprachpaarungen DE-EN und EN-DE implementiert. Die Module für die Übersetzungsrichtungen DE-PL und PL-DE sowie die Interpretation sind entwickelt und werden zurzeit integriert. Die Benutzeroberfläche wurde in Zusammenarbeit mit Mitarbeitenden der Leitstellen aus Dortmund und München konzipiert. Um möglichst realitätsnah einen Notruf simulieren zu können, ist der Demonstrator an eine Telekommunikationsanlage angeschlossen und kann über ein Telefon angerufen werden, während der Testperson in der simulierten Leitstelle wie üblich mit einem PC arbeitet. Das System ist voll-duplex-fähig. Die Sprachkanäle für die anrufende Person und die Leitstellenmitarbeitenden werden separat verarbeitet. Dies ermöglicht u.a. eine Transkription bei gleichzeitigem Sprechen beider Parteien. In Abbildung 2 ist beispielhaft dargestellt, wie die Ausgabe des Gesamtsystems am Bildschirm angezeigt wird. Der Demonstrator läuft aktuell auf einem Server Modell HPE ProLiant DL360 Gen10 mit 256 GB RAM und einer NVIDIA GPU Modell Tesla T4 auf der einige der Berechnungen durchgeführt werden.
Die bisherigen Tests haben gezeigt, dass insbesondere Eigennamen von Personen und Orten noch nicht in jedem Fall korrekt erkannt werden. Demzufolge wurden die o.g. Arbeiten zur Anpassung der Spracherkennungssoftware an den Anwendungsbereich intensiviert. Anhand von Beispielen konnte gezeigt werden, dass die Präzision erwartungsgemäß zunimmt, je mehr Varianten der zu erkennenden Inhalte dem System vorliegen. Aktuell werden laufend Tests durchgeführt, Softwarefehler behoben und die Dienste weiter verbessert, um zum Projektende einen möglichst leistungsfähigen Demonstrator präsentieren zu können.
Fazit & Ausblick
Der im Rahmen des Forschungsprojektes entwickelte Notrufassistent wurde in Form eines Funktionsdemonstrators umgesetzt, der die gewünschte Funktion eines Übersetzungsdienstes beinhaltet. Der Demonstrator soll zusammen mit der im Projekt erstellten Datenbasis den Weg für eine Weiterentwicklung zu einem Produktivsystem ebnen. Hierzu ist – wie zuvor aufgezeigt – eine Härtung der einzelnen Softwareelemente erforderlich. Hervorzuheben ist in diesem Kontext die Automatische Spracherkennung als Kernkomponente des Systems. Erhebliches Potential besteht aus Sicht des Konsortiums in einem Pre-Processing der Audiodaten zur Verbesserung der Wiedergabequalität – bspw. durch Filtern von Hintergrundgeräuschen – was jedoch nicht Gegenstand des Projektes ist. Aufgrund der genannten Herausforderungen ist davon auszugehen, dass es noch eine gewisse Zeit dauern wird, bis die Anwendung robust genug ist, um in einer Leitstelle produktiv eingesetzt zu werden. Angesichts der Geschwindigkeit, mit der die Entwicklungen in diesem Bereich von den div. Akteuren vorangetrieben werden, sollte der Einzug dieser Technologie in das Umfeld Leitstelle jedoch absehbar sein.
Das Projekt NotAs wird gefördert durch das Bundesministerium für Bildung und Forschung im Rahmen der Förderrichtlinie Anwender – Innovativ: Forschung für die zivile Sicherheit II (Förderkennzeichen: 13N15446 ff). Weitere Informationen unter www.sifo.de.
Literatur bei Verfasser
Crisis Prevention 3/2022
Matthias Haack
Stadt Dortmund – Feuerwehr
Institut für Feuerwehr- und Rettungstechnologie
mhaack@stadtdo.de